一、背景
Netlog是一家社交网站社区,目前拥有大规模的应用数据,包括:
超过4000w的活跃用户数、每个月5000w的UV、每月50亿的PV、每月60亿的在线时长、支持26中语言,覆盖5个主要的欧洲国家,如意大利、德国,土耳其等
用户访问的统计视图如下:
数据库统计如下:
大量的数据需要存储,eg. 100+ million 好友关系
互动性强,写操作非常频繁,1.4/1 read-write ratio
在没有做架构改进前,高峰期数据库压力:3000+ queries/sec
相关问题:
随着业务的快速增长,性能问题日益突出,主要瓶颈更多是发生在数据库层,原因如下:
1、web应用堆栈的各个层,大部分是无状态通信的;
2、唯一有状态(或事务)主要发生在数据库层,关系数据库的依赖关系和数据交互导致;
3、传统数据库技术无法满足高性能需要,水平扩展的需求明显;
本文主要是通过开发者视角来介绍Netlog在发展过程中的解决方案和经验。Netlog 基本完全采用开源的解决方案:例如 php, MySQL, Apache, Debian, Memcached, Sphinx, Lighttpd, Squid, 及其它.
二、Netlog数据库系统可伸缩性变化过程
在这个演变过程中,其实跟我上次介绍的另外一篇文章基本类似 “大型网站架构演变和知识体系藏”
第一步:一台DB Server 苦干

这个server 刚开始还是部署在虚拟机环境,承担所有的数据请求和处理,包括web服务器也是在这台机器上(嘿嘿,刚开始的时候,好像所有公司都这个样子,那个时候没有米嘛),后来根据实际情况,把web 服务器和DB 服务器做了一次分离。
第二步:Master-Slave
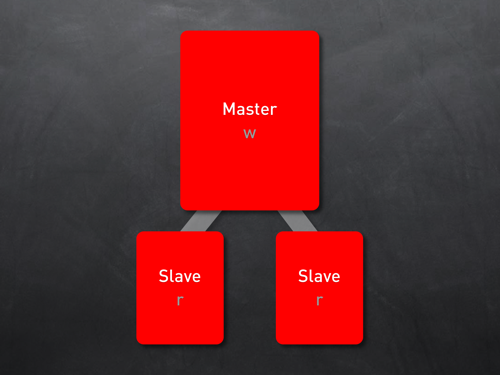
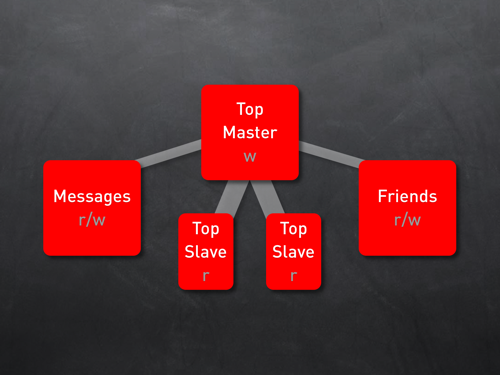
一台DB Server已经无法满足业务增长需要。在这个阶段,根据业务情况可以考虑投入更多的server,通过mysql的复制功能(replication)很容易实现ML的方案。ML方案使你很容易把所有写操作(INSERT/UPDATE/DELETE)跳转到Master Server,而所有读操作(READ)导向Slave Server,因此在某种意义上把数据库压力做了均衡。同时,Slaver Server通过读取Master Server的BinLog文件来保持同步,并把写的请求的数据写到Slave Server中去。
ML方案也存在一些问题,主要包括几个方面:
1、人力方面的投入,如果服务器数量增多的话,在运维上需要投入专门的DBA来运维;
2、可能出现的“replication lag”问题,也就是由于可能出现的读操作堵塞、down机、硬件故障等原因引起的Slave server与Master server数据不同步,从而引起Read的结果是取到过期的数据;
3、数据一致性的问题;
为了解决数据一致性的问题,实际开发中有些技巧,比如对Slave服务器做一些分类,把他们应用在一些诸如搜索/后台服务/统计等数据的Read中会更有效果,因为这些数据查询对实时性要求不高,可以合理避免数据一致性的问题。
Master-Slave模式非常适合读操作频繁的应用。架设你的一台server 承受所有的负载(100%),而读写的比例是4/1,那么相当于你的master server要承受大概80%的select查询,压力非常大,架设这个时候你通过增加一台Slave服务器进来,它能有效的分担select的流量,并且增强整个系统的2倍的能力。所以是一个非常廉价的解决方案。
架设是写操作非常频繁的应用,或者是master sever要承担90%的写操作负载的情况下,通过增加一台slaver server,它仅仅能带来10%的能力提升。因为这个时候,slave服务器要在master和slave服务器之间忙于数据同步,这个时间跟master的90%时间是一致的。在这样的情况下,ML模式仅仅是把read操作分布处理了,而没有分布出来write 操作,其根本原因是你把write traffic 重复了一遍,因此在这个情况下,就没有很好的解决问题。
第三、数据垂直分区
Master/Slave方案有效的解决了Read操作频繁的应用,但是对于SNS这类互动性很强的平台,Write操作也是非常频繁,但是ML却没有办法有效解决这个问题,因此,为了更好的发展,需要对Write 操作进行分布式设计。
常用的对write操作分布式设计的方案是对应用特性级进行垂直划分(Vertical Partitioning)。其实很简单,就是在把业务逻辑划分定义清楚,然后把业务对应的表(数据库)分布部署在不同的服务器,比如Blogs、Photos、Videos等等,要确保这些表没有太多的关联操作和依赖关系。对于每个应用共同的业务,如用户数据,则可以通过数据库复制的方式,把这些公共表部署在每个业务的数据库服务器中去。如下图: